vault backup: 2024-03-16 22:40:04
This commit is contained in:
@@ -175,6 +175,96 @@ plt.show()
|
||||
|
||||
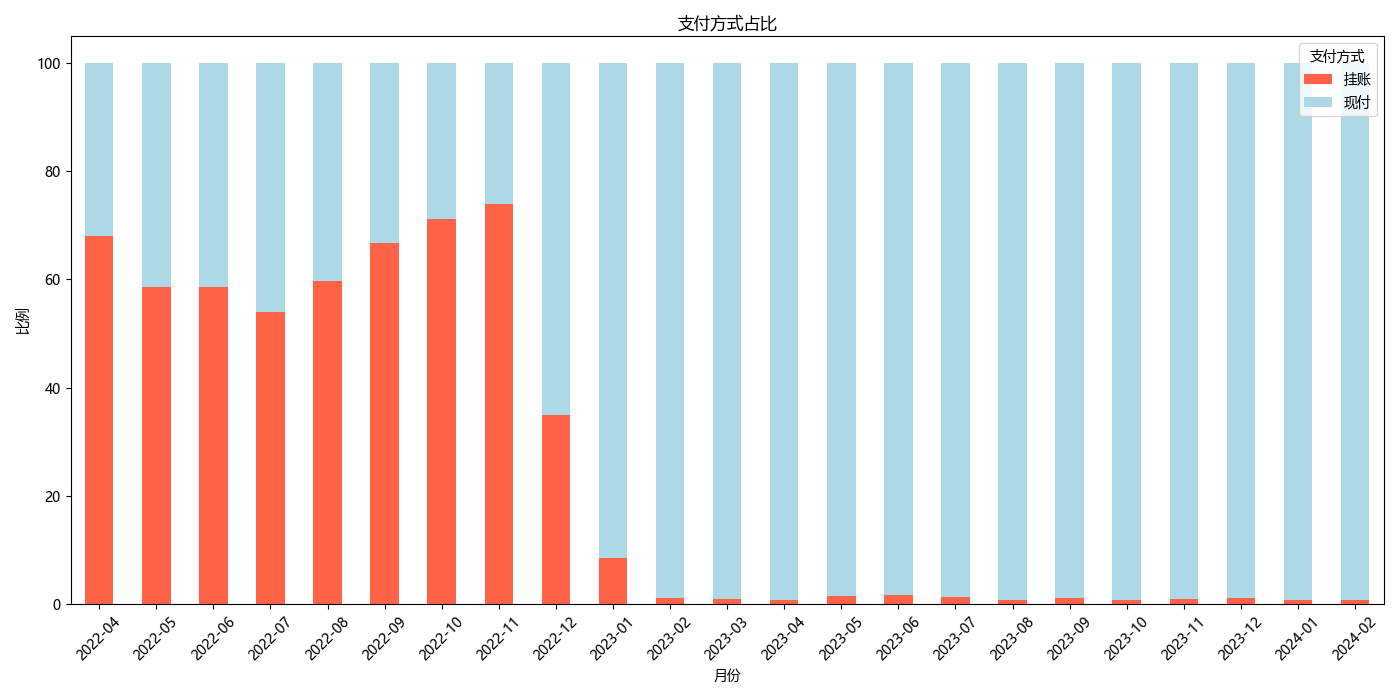
|
||||
|
||||
## 业务类型占比
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
|
||||
|
||||
# Load the Excel file
|
||||
data = pd.read_excel('E:/Projects/analyse/pythonProject/merged_data.xlsx')
|
||||
|
||||
|
||||
# Define the categorization function based on the provided criteria
|
||||
def categorize_business_type(x):
|
||||
if any(keyword in x for keyword in ['保障转运', '密接', '回城', '发热', '送样', '民政任务']):
|
||||
return '疫情'
|
||||
elif any(keyword in x for keyword in ['高铁', '航空', '机场', '救护车']):
|
||||
return '转运'
|
||||
elif '保障' in x:
|
||||
return '保障'
|
||||
else:
|
||||
return '其他'
|
||||
|
||||
|
||||
# Apply the categorization function to the '类型' column to create a new 'Business Category' column
|
||||
data['Business Category'] = data['类型'].apply(categorize_business_type)
|
||||
|
||||
# Calculate the percentage of business for each category
|
||||
business_percentage = data['Business Category'].value_counts(normalize=True) * 100
|
||||
|
||||
# Calculate the revenue share for each business category
|
||||
revenue_share = data.groupby('Business Category')['总成交价'].sum()
|
||||
revenue_share_percentage = (revenue_share / revenue_share.sum()) * 100
|
||||
|
||||
# Plotting the business percentage pie chart
|
||||
plt.figure(figsize=(8, 8))
|
||||
plt.pie(business_percentage, labels=business_percentage.index, autopct='%1.1f%%', startangle=140)
|
||||
plt.title('业务类型占比')
|
||||
plt.show()
|
||||
|
||||
# Plotting the revenue share percentage pie chart
|
||||
plt.figure(figsize=(8, 8))
|
||||
plt.pie(revenue_share_percentage, labels=revenue_share_percentage.index, autopct='%1.1f%%', startangle=140)
|
||||
plt.title('业务营收占比')
|
||||
plt.show()
|
||||
```
|
||||
|
||||
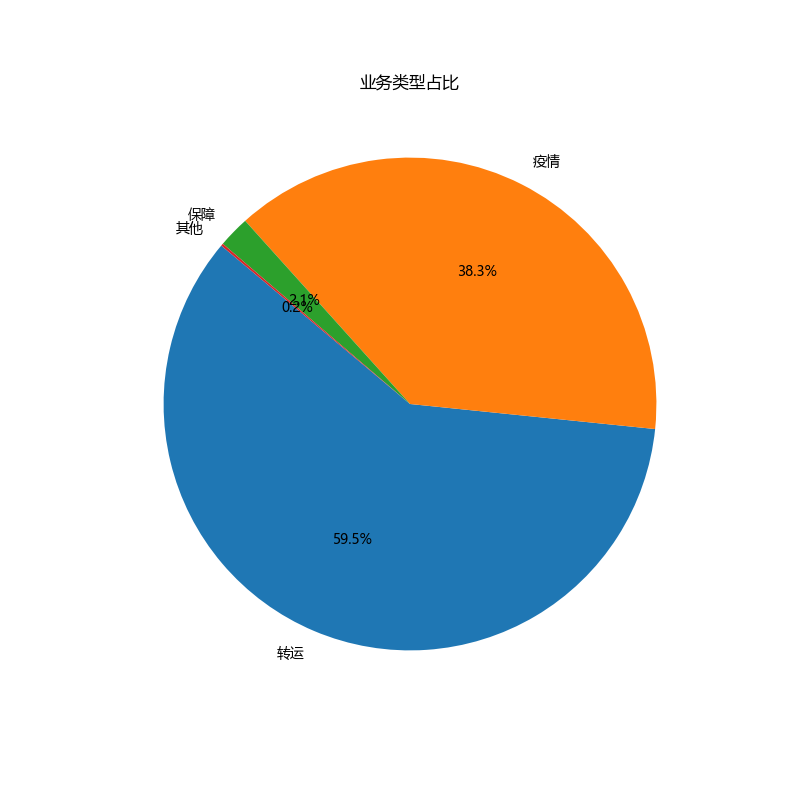
|
||||
|
||||
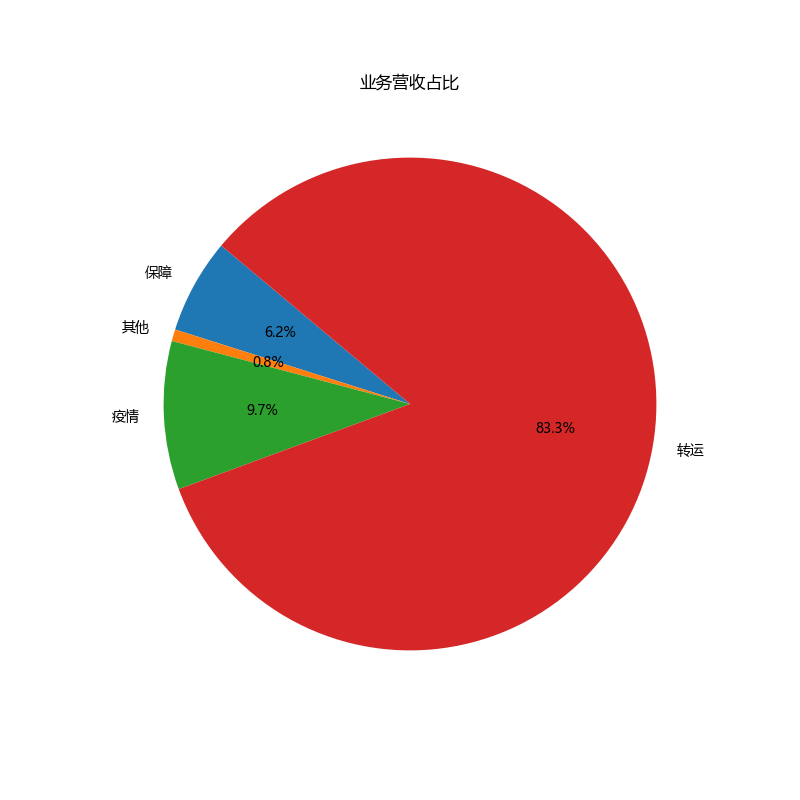
|
||||
|
||||
## 业务区域分布
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
import matplotlib.pyplot as plt
|
||||
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
|
||||
|
||||
# Load the Excel file
|
||||
data = pd.read_excel('E:/Projects/analyse/pythonProject/merged_data.xlsx')
|
||||
|
||||
# Correcting the approach based on the updated description for the '区域' column
|
||||
|
||||
# Update the DataFrame to reflect the correct column name and values for categorization
|
||||
data['Regional Category'] = data['区域'].map({'市内': '省内', '广东省内': '省内', '国际': '省外', '港澳台': '省外', '广东省外': '省外'})
|
||||
|
||||
# Calculate the distribution of the new categories
|
||||
regional_category_distribution = data['Regional Category'].value_counts()
|
||||
|
||||
# Generate a pie chart to show the updated regional distribution of the business
|
||||
plt.figure(figsize=(8, 8))
|
||||
plt.pie(regional_category_distribution, labels=regional_category_distribution.index, autopct='%1.1f%%', startangle=140, colors=['skyblue', 'orange'])
|
||||
plt.title('业务区域分布')
|
||||
plt.show()
|
||||
|
||||
# Next, group by the new regional category and sum the revenues
|
||||
revenue_by_category = data.groupby('Regional Category')['总成交价'].sum()
|
||||
|
||||
# For the pie chart, we can directly use the revenue_by_category Series
|
||||
# The index of this Series will be the labels, and the values will be the sizes for each pie slice
|
||||
plt.figure(figsize=(8, 8))
|
||||
plt.pie(revenue_by_category, labels=revenue_by_category.index, autopct='%1.1f%%', startangle=140, colors=['skyblue', 'orange'])
|
||||
plt.title('营收贡献占比')
|
||||
plt.show()
|
||||
```
|
||||
|
||||
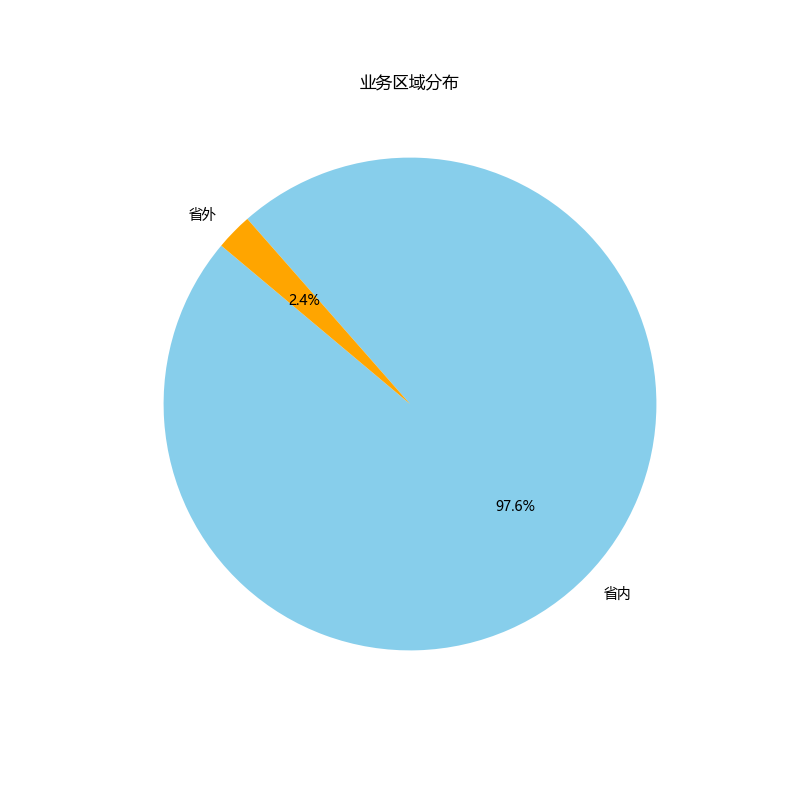
|
||||
|
||||
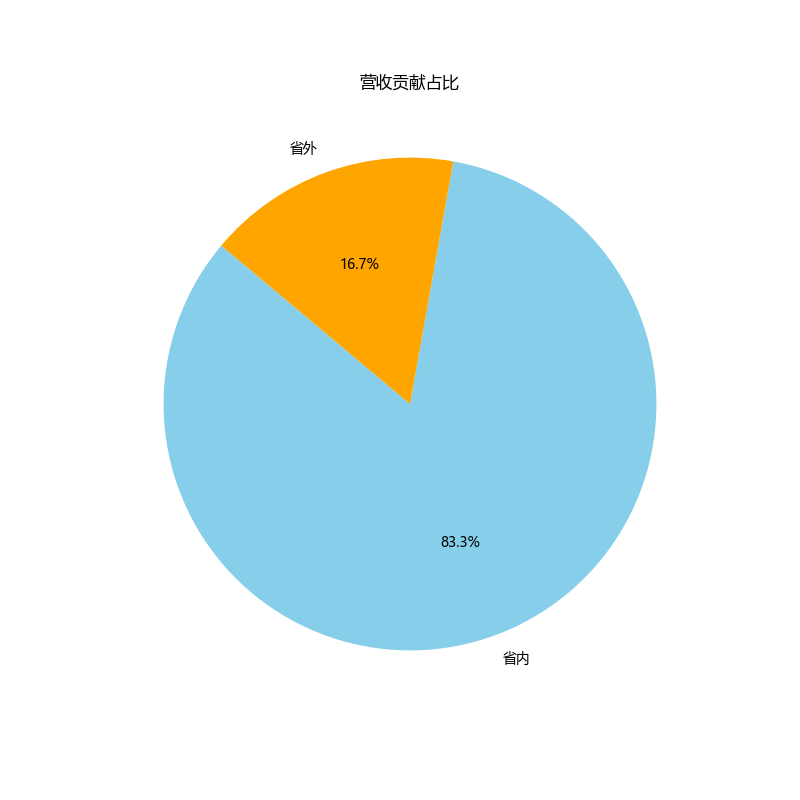
|
||||
|
||||
## 业务时段分布
|
||||
|
||||
```python
|
||||
@@ -280,7 +370,7 @@ plt.show()
|
||||
|
||||
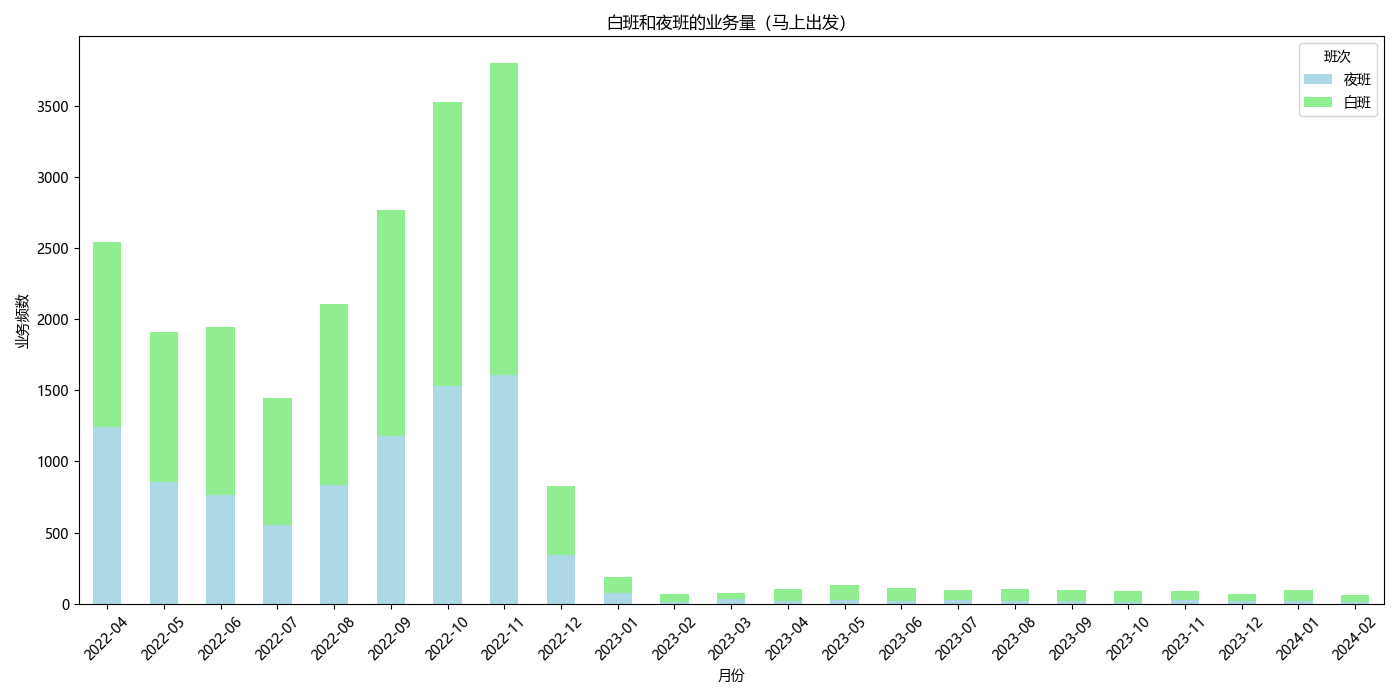
|
||||
|
||||
更进一步,剔除掉疫情期间的所有业务,能够
|
||||
更进一步,剔除掉疫情期间的所有业务,能够较为客观地反映现在的情况
|
||||
|
||||
```python
|
||||
# Filter for immediate departures after December 2022
|
||||
@@ -312,43 +402,3 @@ plt.show()
|
||||
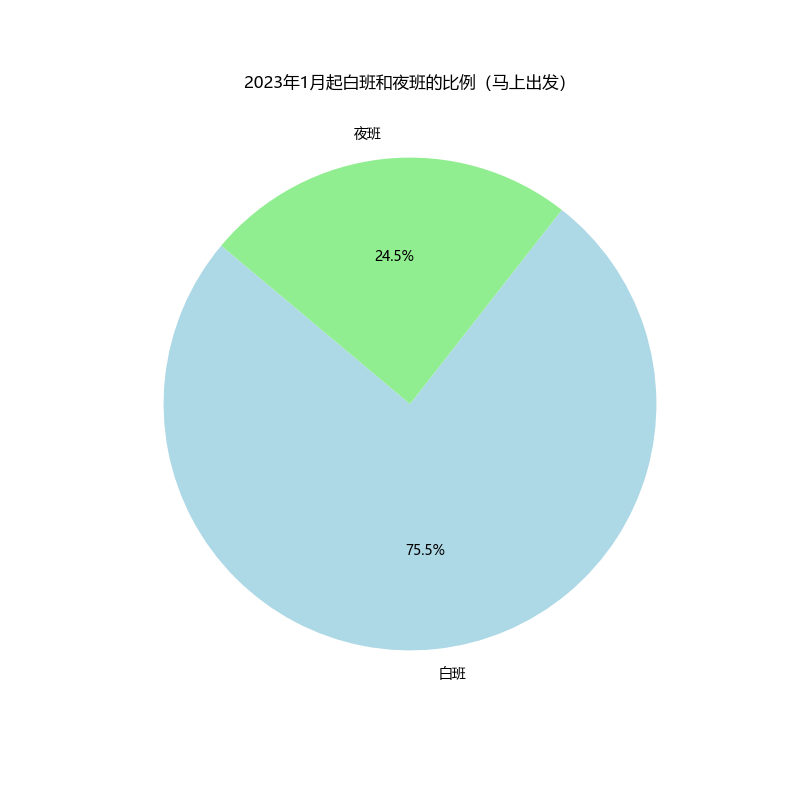
|
||||
|
||||
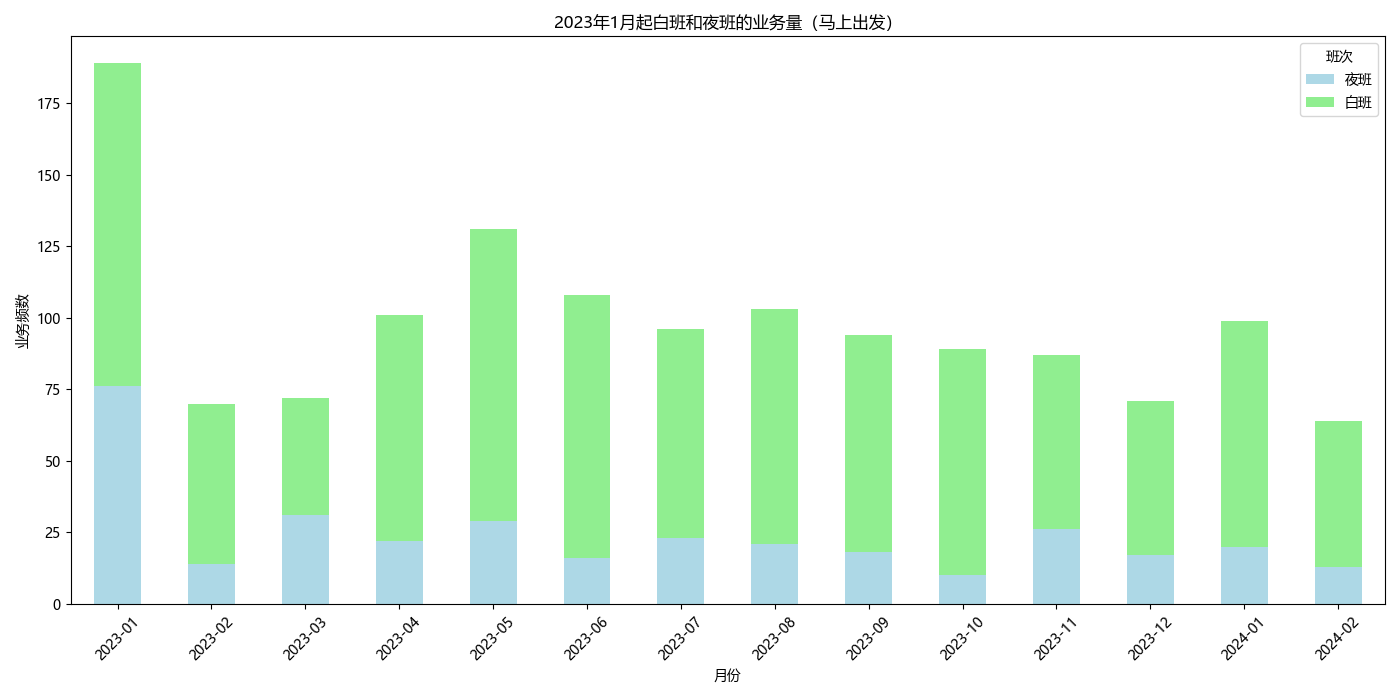
|
||||
|
||||
## 业务区域分布
|
||||
|
||||
```python
|
||||
import pandas as pd
|
||||
import matplotlib.pyplot as plt
|
||||
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
|
||||
|
||||
# Load the Excel file
|
||||
data = pd.read_excel('E:/Projects/analyse/pythonProject/merged_data.xlsx')
|
||||
|
||||
# Correcting the approach based on the updated description for the '区域' column
|
||||
|
||||
# Update the DataFrame to reflect the correct column name and values for categorization
|
||||
data['Regional Category'] = data['区域'].map({'市内': '省内', '广东省内': '省内', '国际': '省外', '港澳台': '省外', '广东省外': '省外'})
|
||||
|
||||
# Calculate the distribution of the new categories
|
||||
regional_category_distribution = data['Regional Category'].value_counts()
|
||||
|
||||
# Generate a pie chart to show the updated regional distribution of the business
|
||||
plt.figure(figsize=(8, 8))
|
||||
plt.pie(regional_category_distribution, labels=regional_category_distribution.index, autopct='%1.1f%%', startangle=140, colors=['skyblue', 'orange'])
|
||||
plt.title('业务区域分布')
|
||||
plt.show()
|
||||
|
||||
# Next, group by the new regional category and sum the revenues
|
||||
revenue_by_category = data.groupby('Regional Category')['总成交价'].sum()
|
||||
|
||||
# For the pie chart, we can directly use the revenue_by_category Series
|
||||
# The index of this Series will be the labels, and the values will be the sizes for each pie slice
|
||||
plt.figure(figsize=(8, 8))
|
||||
plt.pie(revenue_by_category, labels=revenue_by_category.index, autopct='%1.1f%%', startangle=140, colors=['skyblue', 'orange'])
|
||||
plt.title('营收贡献占比')
|
||||
plt.show()
|
||||
```
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
Reference in New Issue
Block a user